|
|
|
Genome Magician
Ultra fast local DNA sequence search for NGS data
|
|

|

|
GenomeMagician is a software for fast DNA sequence queries/searches (like a local BLAST) AND alignment of a query sequence with local databases (FASTA-format).
Features:
- Ultra fast motif search for large local DNA sequence datasets (*.fasta and *.fastq-files)
- Performs a fast DNA sequence search for finding matches if a query DNA sequence in a local database (FASTA- and FASTQ-format).
- GenomeMagician is very useful for finding similarities in next generation sequencing projects (NXT) as produced by high-throughput sequencers (NGS, next generation sequencing, Illumina (Solexa) sequencing, Roche 454 sequencing, Ion Torrent: Proton / PGM sequencing etc.) and as provided by NCBI Sequence Read Archive (https://www.ncbi.nlm.nih.gov/sra).
- Reads FASTA- and FASTQ-files as query sequence and sequence databases.
- Exports query results (matches with defined minimum number of matching base pairs and minimum percent identiy) in FASTA-files.
- Add query sequence or databases by drag & drop from the file explorer.
- Tabbed queries: Open new query tabs.
- Take matching sequences found in a previous query as new query sequence in a new tab.
How to install the software:
- Download the ZIP-archive.
- Unpack. No installation is required.
- Run "GenomeMagician.exe".
- The software automatically downloads a trial license valid for 30 days from first program start.
How to use Genome Magician software:
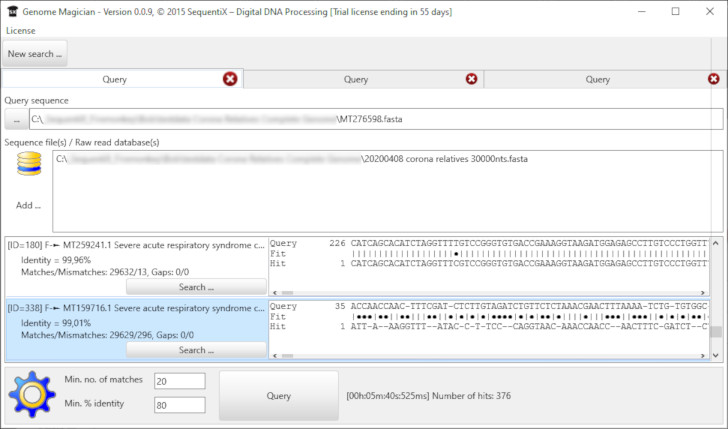
- Click the "New search ..." button. This will open a new query tab.
- Click "..." from the Query sequence panel to open a query sequence (FASTA-format) from the local hard disc.
- Click "Add ..." to choose one ore more database files (FASTA-format).
- If necessary adopt the matching parameters:
"Min.no. of matches": the number of nucleotides that have to match.
"Min. % identity": the minimum percentual identity in a fitting nucleotide stretch of minimum length of "Min.no. of matches".
- Click "Query" to start the query.
GenomeMagician creates a fast index file for each selectd database for its first time use. This will require some time but will speed up any further queries.
- Export your data as a text file (ASCII) as alignments.
Hints:
The time limiting process is the alignment of the query sequence with the database mataches. The more hits are found and the longer the query sequence and the hit sequences are, the longer the process will last.
Uses multitasking: The more processor cores there are, the faster the query and alignment will be.
Keywords:
fast local DNA sequence query, alignment, FASTA, FASTQ, next generation sequencing, Illumina, software, genbank
|
|